Los videos y el texto de esta sesión son complementarios. Los videos amplían el contexto histórico y conceptual; el texto va a los mecanismos y te pone a interactuar con ellos. Encontrarás ideas en los videos que el texto no repite exactamente. ¡Disfruta de esta dinámica!
Introducción
En la sesión 3 describimos cómo funciona el algoritmo árbol de decisión: el modelo hace preguntas binarias [sí/no] sobre los datos hasta llegar a una respuesta.
Ahora vamos a hacer exactamente lo mismo, pero con Python 🐍. No es necesario memorizar el código, la idea es que puedas comprender qué hace cada línea y conectarla con conceptos que ya conoces.
Cinco pasos que todo modelo de Machine Learning recorre
Antes de pasar al código, vamos a familiarizarnos con el flujo de un modelo de machine learning (aprendizaje de máquinas). Cada sección un experimento corresponde a uno de estos pasos.
📦DatosLos ejemplos etiquetados que el modelo usará para aprender.
→
✂️SepararDividir en dos grupos: uno para aprender (train = datos de entrenamiento), uno para evaluar (test = datos de prueba).
→
🏋️EntrenarEl modelo estudia el grupo de entrenamiento y construye reglas.
→
🔮PredecirEl modelo recibe ejemplos nuevos y decide qué cree que son, dado lo aprendido en el entrenamiento.
→
📊EvaluarComparamos las predicciones del modelo contra los datos etiquetados ("ground truth").
Estos cinco pasos son universales. Un modelo que detecta tumores en radiografías, uno que predice el precio de una casa o uno que reconoce tu voz siguen exactamente este flujo de trabajo.
¿Por qué dividimos los datos?
Imagina que estudias para un examen con una guía de estudio: cada pregunta tiene una respuesta. Si el día del examen el profesor usa exactamente las mismas preguntas, probablemente saques una calificación perfecta. Pero eso no significa que hayas aprendido el material, puede ser que simplemente memorizaste las respuestas de las preguntas en la guía.
Con los modelos de machine learning pasa exactamente lo mismo. Si evaluamos el modelo con las mismas imágenes que usamos para entrenar, el modelo puede “recordar” las respuestas correctas sin haber aprendido patrones que le ayuden a predecir nuevas imágenes.
La solución a este problema en particular es: separar los datos antes de empezar.
Las 1,797 imágenes del dataset digits
Entrenamiento · 75% · 1,347 imágenes
Prueba · 25% · 450
El modelo puede ver estas imágenes muchas veces durante el entrenamiento.
Estas imágenes quedan bloqueadas hasta la evaluación final. El modelo nunca las ve antes.
¡Ojo! Nunca uses los datos de prueba durante el entrenamiento. La precisión que obtienes al final solo tiene sentido si el modelo no vio esas imágenes antes.
Experimento: reconocer dígitos escritos a mano
Para nuestro primer experimento en Pytho, usaremos un conjunto de datos que se llama digits. Contiene 1,797 imágenes en escala de grises de dígitos escritos a mano (del 0 al 9), cada una de 8×8 píxeles. Es pequeño, claro y perfecto para empezar.
Primero observa cómo se ven algunos de estos dígitos:
Figure 1: Diez imágenes del dataset digits. Cada una tiene 8×8 píxeles y una etiqueta que indica qué número es.
Cada imagen es una cuadrícula de 8×8 = 64 valores numéricos entre 0 (blanco) y 16 (negro). Eso es lo que el algoritmo de machine learning árbol de decisión va a analizar para decidir qué dígito es cada imagen. ¿Por qué usamos este algorimo en específico? Esta es una pregunta que tú ya puedes responder. Vuelve a la sesión 3 si es necesario, y reflexiona si otros modelos, arquitecturas, u algoritmos podrían usarse para este apliación.
Google Colab — tu laboratorio
Para escribir y ejecutar Python no necesitas instalar algo nuevo en tu computadora. Para empezar, puedes usar Google Colab: un cuaderno de código que corre directo en el navegador.
mi_modelo.ipynb● Conectado
+ Código+ TextoArchivoEntorno de ejecuciónVer
Sesión 12: vamos a construir un árbol de decisión que reconoce dígitos escritos a mano.
# Cargar datos y entrenar el árbolfromsklearn.datasetsimportload_digitsfromsklearn.treeimportDecisionTreeClassifierprint("Listo para reconocer números")
Listo para reconocer números
+ Agregar celda de código+ Agregar celda de texto
Para usar Google Colab necesitas una cuenta de Google. Crea un cuaderno nuevo desde “Archivo → Nuevo notebook” y copia el código de esta sesión.
Introducción breve a Python
Abajo una breve introducción a las cuatro piezas esenciales del lenguaje de programación Python. Si dominas estas cuatro piezas, podrás seguir la sesión sin problema. No se requiere ser un experto en el lenguaje, pero sí tener estas 4 piezas presentes al momento de leer o escribir tu código.
01 · Variables
Guardar algo con nombre
Una 'variable' guarda un valor para reutilizarlo después. digits, modelo y score son todas variables.
modelo=DecisionTreeClassifier()
02 · Funciones y métodos
Pedir que algo haga una tarea
Los paréntesis () indican que se ejecuta una acción. load_digits() carga datos. modelo.fit() entrena el árbol.
modelo.fit(X_train, y_train)
03 · Índices
Elegir un ejemplo concreto
X_test[12] significa: dame el ejemplo número 12 del grupo de prueba. Los corchetes [ ] sirven para elegir elementos.
imagen=X_test[12]
04 · print()
Mostrar un resultado en pantalla
Todo lo que quieras ver pasa por print(). Úsalo para inspeccionar la precisión, la predicción o cualquier variable.
print(score)
Del árbol de decisión al código: cada línea explicada
Con los cinco pasos del flujo de ML en mente y una idea general de cómo funciona Python, ya puedes leer el experimento completo. Haz clic en cualquier línea para ver qué hace exactamente.
mi_modelo.py← haz clic en una línea para entenderla
17# ── Paso 4: Entrenar (aquí ocurre el aprendizaje) ─────
18modelo.fit(X_train,y_train)
19
20# ── Paso 5: Predecir y evaluar ────────────────────────
21prediccion=modelo.predict([X_test[12]])[0]
22score=modelo.score(X_test,y_test)
23print(f"Precisión: {score:.3f}")
Output »Precisión: 0.836
👆
Haz clic en cualquier línea para ver su explicación.
El árbol en acción
Ahora vamos a ver el modelo desde tres ángulos: una predicción individual, las preguntas que aprendió el árbol y el patrón general de aciertos y errores. Así pasamos de programar unas líneas de código a analizar el resultado y entender qué es lo que está haciendo.
Antes de evaluar todo el modelo, empecemos con un solo caso. Vamos a tomar una imagen del grupo de prueba (X_test); es decir, una imagen que el modelo no vio durante el entrenamiento, y le pediremos que nos diga qué dígito cree que es.
En este bloque, las primeras líneas repiten el experimento completo para que el ejemplo funcione por sí solo: cargar datos, separar entrenamiento/prueba, crear el árbol y entrenarlo. A partir de indice = 12 estaremos viendo algo nuevo. Ahí es donde elegimos una imagen específica, comparamos la respuesta correcta (real) con la respuesta del modelo (prediccion) y mostramos el resultado.
Figure 2: Una imagen del grupo de prueba con la predicción del árbol. El modelo puede acertar o equivocarse.
Precisión global: 0.836 (376/450 imágenes de prueba)
Esta predicción individual nos ayuda a ver cómo se comporta el modelo en un caso concreto, pero esto no basta para saber si el modelo funciona bien en general. Para eso necesitamos mirar muchas predicciones juntas. Para ello, primero veremos qué preguntas aprendió a hacer el árbol y después analizaremos sus errores con una matriz de confusión.
2 · El árbol de decisión: las preguntas que hace el modelo
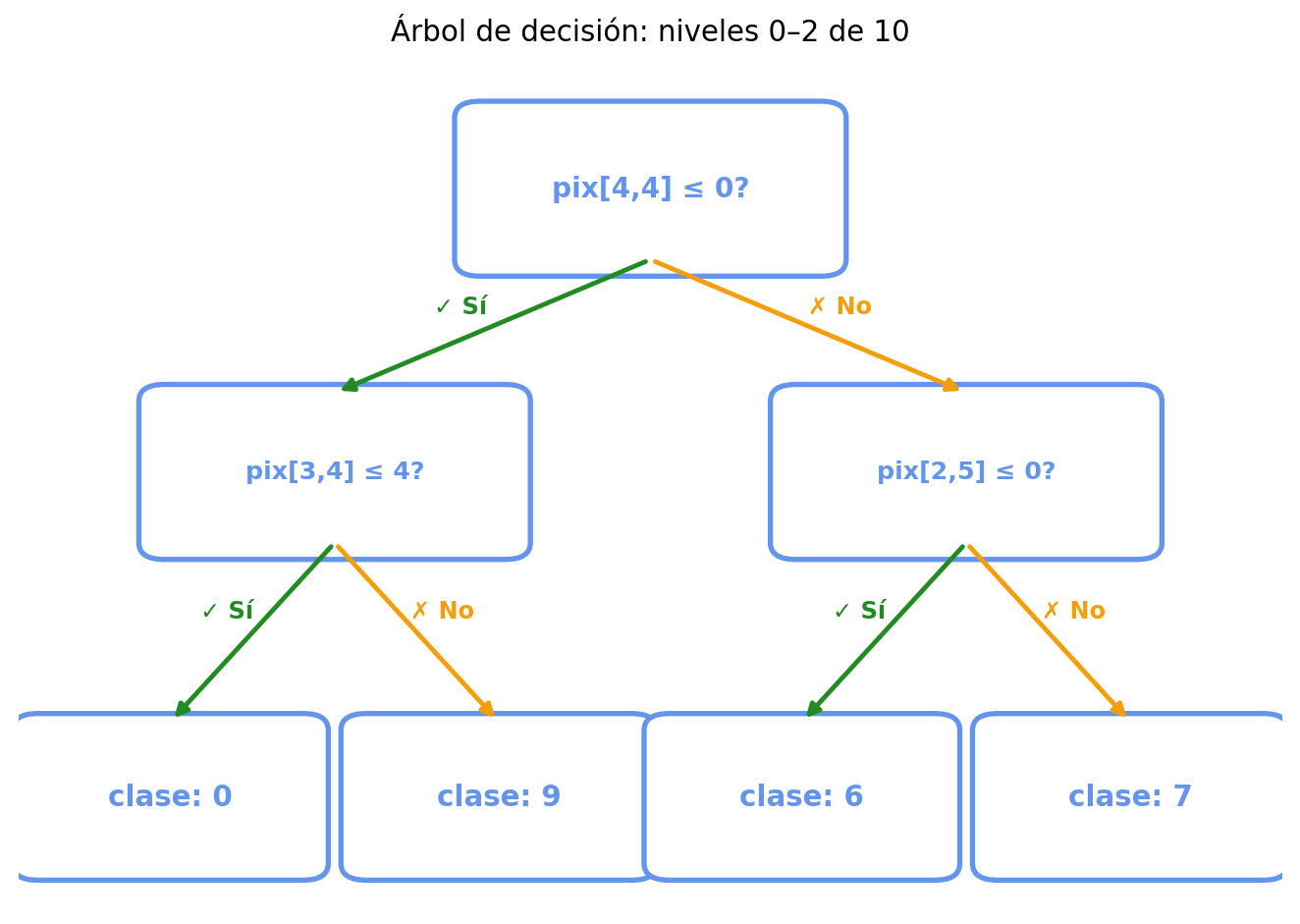
Aquí está lo que construyó Python. Cada nodo hace una pregunta sobre el valor de un píxel: si la respuesta es sí (≤ umbral), el árbol va a la izquierda; si no, va a la derecha. El árbol completo tiene 10 niveles. Aquí mostramos los primeros 3 para que la imagen sea legible.
Figure 3: Primeros 3 niveles del árbol de decisión. Cada nodo hace una pregunta sobre el valor de un píxel; según la respuesta (✓ Sí / ✗ No) el árbol toma una rama. Los nodos del fondo muestran la clase predicha en ese punto. El árbol completo tiene 10 niveles.
Cómo leer este diagrama
Lee el árbol de arriba hacia abajo. Cada recuadro azul es una pregunta sobre un píxel específico de la imagen. Según la respuesta, el árbol toma una rama:
Flecha verde → Sí: el valor de ese píxel es menor o igual al umbral → el árbol sigue por la rama izquierda.
Flecha naranja → No: el valor de ese píxel es mayor que el umbral → el árbol sigue por la rama derecha.
Los recuadros inferiores visibles muestran qué dígito parece más probable si una imagen llega hasta ese punto. No son necesariamente la predicción final: este diagrama solo muestra los primeros 3 niveles para que se pueda leer con claridad.
El árbol final puede seguir haciendo más preguntas, hasta un máximo de 10 niveles. Al final de ese recorrido, el modelo da su predicción.
Esto es el árbol de decisión que describimos en la sesión 3, ahora construido automáticamente por Python a partir de 1,347 ejemplos. Cada pregunta y cada umbral fueron elegidos por el algoritmo durante el entrenamiento para separar mejor los dígitos.
3 · ¿Dónde acierta el árbol y dónde se confunde? La matriz de confusión
Ver el código de la matriz de confusión
import matplotlib.pyplot as pltfrom sklearn.metrics import ConfusionMatrixDisplayfig, ax = plt.subplots()ConfusionMatrixDisplay.from_estimator( modelo, X_test, y_test, ax=ax, colorbar=False, cmap="Blues",)ax.set_title("Matriz de confusión")plt.tight_layout()plt.show()
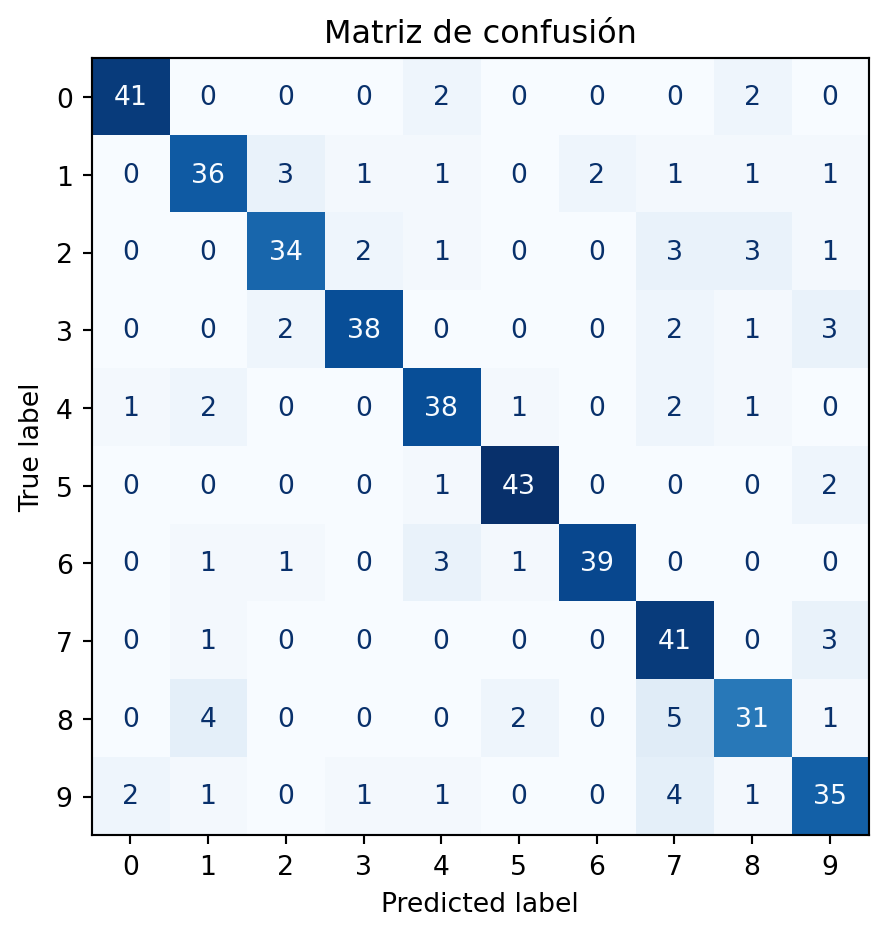
Figure 4: Cada fila es el dígito real; cada columna es lo que predijo el modelo. La diagonal brillante son aciertos. Los cuadros fuera de la diagonal son errores.
¿Cómo leer la matriz de confusión?
La matriz resume las 450 predicciones del grupo de prueba. En vez de mirar una imagen a la vez, aquí vemos todos los aciertos y errores juntos.
Cada fila y cada columna representa un dígito del 0 al 9:
Fila: el dígito correcto de la imagen.
Columna: el dígito que predijo el modelo.
Número en la celda: cuántas imágenes tuvieron esa combinación exacta.
La diagonal muestra los aciertos. Son las celdas donde la fila y la columna coinciden: por ejemplo, fila 0 / columna 0 significa que la imagen era un 0 y el modelo predijo 0. Cuanto más azul sea una celda de la diagonal, más veces acertó el modelo en ese dígito.
Las celdas fuera de la diagonal muestran errores. Por ejemplo, fila 3 / columna 8 significa: la imagen era un 3, pero el modelo predijo 8. Cuanto más azul sea una celda fuera de la diagonal, más frecuente fue ese tipo de confusión.
Para encontrar el error más común del modelo:
Ignora la diagonal.
Busca la celda más azul fuera de la diagonal.
Lee la fila para saber cuál era el dígito correcto.
Lee la columna para saber qué predijo el modelo.
Pregúntate si esos dos dígitos se parecen visualmente y por qué el árbol pudo confundirlos.
Actividad: tres experimentos
Vamos a intentar mejorar nuestro modelo. El árbol original acierta cerca del ~84% de las veces. Lo que haremos es cambiar los parámetros del modelo. A cada modificación le denominaremos experimento. Cada experimento tiene un objetivo claro, no hace falta dominar todo el código completo para aprender algo valioso de estos ejercicios.
Experimento A · ¿Cuántas preguntas necesita el árbol?
El parámetro max_depth controla el número máximo de preguntas que puede hacer el árbol antes de dar una respuesta. Busca la línea DecisionTreeClassifier(max_depth=10, ...) y prueba estos valores uno por uno, corriendo el código completo cada vez:
Valor
Qué significa
Precisión esperada
max_depth=2
Solo 2 preguntas — árbol muy simple
~31 %
max_depth=5
5 preguntas — árbol moderado
~66 %
max_depth=10
El original
~84 %
max_depth=None
Sin límite — el árbol crece todo lo que pueda
~82 %
El peligro de un árbol sin límite
Un árbol sin max_depth corre el riesgo de memorizar cada imagen de entrenamiento en vez de aprender patrones y establecer reglas generales. Algo así como estudiar copiando las respuestas de la guía de estudio pero sin entender el contenido. En la etapa de entrenamiento funciona perfectamente; con imágenes nuevas, falla. A esto se llama sobreajuste.
¿Por qué un árbol con solo 2 preguntas acierta tan poco? ¿Y por qué quitarle el límite tampoco mejora mucho?
Experimento B · Dale nombre a un error de la matriz
La matriz de confusión te dice qué pares de dígitos “confunde” el modelo. Ahora vas a encontrar ese error en una imagen:
Mira la matriz y localiza la celda más brillante fuera de la diagonal. Anota: ¿qué dígito (fila) se confunde con qué predicción (columna)?
Busca la línea indice = 12 y cámbiala por números entre 0 y 449 hasta que el modelo cometa ese error exacto; es decir, que prediga el dígito incorrecto que encontraste en el paso 1.
Observa la imagen: ¿puedes ver a simple vista por qué el árbol se confundió?
¿Esos dos dígitos se parecen visualmente cuando alguien los escribe a mano? ¿Crees que un humano también los confundiría?
Experimento C · ¿Qué pasa si el árbol aprende con menos datos?
Busca la línea test_size=0.25 y cámbiala por test_size=0.5. Esto mueve el 50 % de las imágenes al grupo de prueba y hace que el árbol aprenda solo con las 898 imágenes restantes en vez de las 1,347 originales.
¿Sube o baja la precisión? ¿Por qué crees que tener menos imágenes de entrenamiento cambia el resultado?
IA como copiloto del experimento
Úsalo ya
Explícame este bloque
Pega unas pocas líneas y pide que te las traduzca a lenguaje natural. Más útil que buscar en Google.
"Explícame qué hacen estas líneas como si nunca hubiera programado: modelo = DecisionTreeClassifier(max_depth=10), modelo.fit(X_train, y_train), score = modelo.score(X_test, y_test)"
Úsalo ya
Tengo un error
Pega el mensaje exacto del error y tu código. La IA puede identificar qué salió mal mucho más rápido que intentarlo a ciegas.
"Me salió este error en Python: NameError: name 'X_train' is not defined. Aquí está mi código completo. ¿Qué estoy haciendo mal?"
Úsalo con criterio
¿Qué pasa si…?
Cuando ya entiendes el experimento, puedes preguntarle a la IA qué efecto tendrá cambiar un parámetro antes de correrlo.
"En mi árbol de decisión, si cambio max_depth de 10 a 2, ¿qué efecto esperas en la precisión y por qué? Explícalo en términos simples."
Qué aprendiste de ML y qué aprendiste de Python
De machine learning
Un modelo aprende de ejemplos etiquetados; nadie le programó las reglas a mano.
La separación entrenamiento/prueba es la condición mínima para que la precisión tenga significado; es decir, la condición mínima para evaluar nuestro modelo. Sin ella, no sabes si el modelo aprendió patrones o memorizó los datos.
La profundidad del árbol es un arma de doble filo: muy baja = no aprende lo suficiente, sin límite = memoriza en vez de generalizar. El punto óptimo está en el medio (y te toca a ti encontrarlo).
La matriz de confusión te dice qué errores comete el modelo, no solo cuántos, es un excelente complemento para la precisión, cuando queremos evaluar y mejorar nuestro modelo.
De Python
Con pocas líneas de sklearn puedes entrenar un clasificador que reconoce el ~84 % de imágenes de dígitos que nunca ha visto.
Un solo parámetro (max_depth, test_size) puede cambiar el resultado por completo.
Modificar un experimento existente ya es programar, no hace falta empezar desde cero.
Reflexión · 5 min
Actividad de reflexión
01
¿Habías escrito código antes de esta sesión? Si nunca lo habías hecho, ¿qué se te hizo más extraño o más natural? Si ya sabías programar, ¿qué fue distinto a usar otros lenguajes?
02
¿En qué se parece estudiar para un examen a entrenar un modelo? Piensa en la guía de estudio, en preguntas que ya viste y en preguntas nuevas. ¿Qué sería el "sobreajuste" en tu propia forma de estudiar?
03
Si tuvieras que entrenar un modelo para algo de tu vida (por ejemplo, predecir cuánto tiempo te tomará llegar a la escuela), ¿qué datos etiquetados necesitarías? ¿Qué cosas serían difíciles de medir?
04
Explícale a alguien menor que tú, en dos oraciones, por qué un modelo de machine learning con 100 % de precisión en entrenamiento no necesariamente es un buen modelo.
No hay respuestas correctas o incorrectas. El objetivo es que empieces a ver el código y los datos con familiaridad.
La idea central de esta sesión
Idea central · Sesión 12
Tu primer modelo en Python no aprendió porque alguien le escribió reglas a mano, sino porque encontró patrones en ejemplos etiquetados. Eso significa que la calidad de un modelo depende directamente de los datos con los que aprendió. La próxima vez que escuches “una IA hace X”, ya sabes qué preguntar antes que nada: ¿con qué ejemplos la entrenaron y cómo comprobaron su desempeño con datos que nunca había visto?