
¿Tus datos ya tienen respuestas correctas etiqutadas?
Si alguien ya etiquetó los ejemplos con la respuesta correcta, estás en el mundo del aprendizaje supervisado.
Los videos y el texto de esta sesión son complementarios. Los videos amplían el contexto histórico y conceptual; el texto va a los mecanismos y te pone a interactuar con ellos. Encontrarás ideas en los videos que el texto no repite exactamente. ¡Disfruta de esta dinámica!
En esta sesión nos enfocaremos en darte un panorama global de los algoritmos más conocidos de la inteligencia artificial, y te ofreceremos una guía para saber cuándo debes usar cada uno de ellos, y por qué.
¿Por qué es importante aprender sobre distintos algoritmos? Empecemos con una analogía: cuando un carpintero va a la obra, lleva consigo una caja con múltiples herramientas. Del mismo modo, un médico recurre a distintos análisis según la sintomatología del paciente y el tipo de información que necesita obtener. Con la inteligencia artificial ocurre algo similar: existen muchos modelos, algoritmos, métodos, y cada uno resulta especialmente útil para ciertos tipos de problemas.
En esta sesión nos enfocaremos en 6 ejemplos representativos de modelos, algoritmos y arquitecturas de aprendizaje automático, con el objetivo de ofrecerte una visión general de cómo se organizan y para qué sirve cada uno.
Antes de elegir un método, es fundamental reconocer la naturaleza del desafío. Algunos sirven para predecir números, otros para clasificar imágenes o descubrir grupos en datos sin etiquetas. Entender qué tipo de problema tienes delante es lo que marca la diferencia al trabajar con IA.
En inteligencia artificial, la elección del método influye directamente en el tipo de resultado que podemos obtener. Algunos algoritmos están pensados para prever valores, otros para reconocer patrones, otros más para agrupar datos con rasgos similares. Cada uno responde mejor a ciertos problemas y presenta limitaciones en otros.
Pensemos, por ejemplo, en la regresión lineal. Este método es útil cuando se quiere estimar una cantidad continua, como el precio de una vivienda o la evolución de una variable económica. En cambio, si el objetivo es separar correos entre “spam” y “no spam”, lo más eficaz es un algoritmo de clasificación. Y si lo que buscamos es descubrir grupos dentro de un conjunto de datos sin etiquetas, entonces tiene más sentido recurrir a técnicas de agrupamiento, como K-Means.
También hay casos en los que algunos modelos resultan desproporcionados para el tipo de tarea a resolver. Un transformer puede ser una opción potente para procesar texto, pero no siempre es la elección más sensata cuando se trata de problemas sencillos, estructurados y con pocos datos. En esos casos, un modelo más simple puede ofrecer resultados igual de buenos, con menos costo de entrenamiento, menos complejidad y mayor facilidad de interpretación.
A lo largo de esta sesión revisaremos precisamente eso: qué tipo de problemas resuelve mejor cada enfoque algorítmico y qué criterios nos ayudan a elegir entre ellos. Comprender esa relación entre problema y método es la base para trabajar con la inteligencia artificial de forma rigurosa y eficaz.
Antes de elegir un algoritmo, conviene detenerse un momento y mirar el problema con calma. La selección del método depende sobre todo de dos cosas: si los datos ya tienen respuestas correctas y qué tipo de resultado queremos obtener.
Esta distinción puede parecer simple, pero en realidad organiza gran parte del campo. No es lo mismo trabajar con ejemplos ya clasificados que con datos sin etiquetar, ni es igual predecir una cantidad continua que identificar una categoría, descubrir grupos ocultos o decidir una acción dentro de un entorno.
Por eso, una buena forma de orientarse es empezar con dos preguntas básicas:
Si alguien ya etiquetó los ejemplos con la respuesta correcta, estás en el mundo del aprendizaje supervisado.
Puede ser un número, una categoría, un grupo emergente o una acción dentro de un entorno.
Pregunta 1: ¿Tienes respuestas correctas etiquetadas en tus datos?
Pregunta 2: ¿Qué forma tiene la salida?
Este esquema no pretende tener la respuesta a todos los problemas. Su función es ayudarte a reconocer el punto de partida correcto, porque elegir bien el tipo de problema es el primer paso para escoger el método adecuado.
Ejemplo paso a paso
"Quiero predecir cuánto tardará un pedido de UberEats."
¿Tienes respuestas etiquetadas? Sí — un historial de tiempos de entrega de UberEats de los últimos años.
¿Qué forma tiene la salida? Un número continuo (minutos).
Regresión lineal. Predice un número a partir de datos etiquetados.
Ahora sí, pasemos de la orientación general a los casos concretos. En las siguientes páginas recorreremos los seis métodos del mapa anterior para entender qué problema aborda cada uno, qué tipo de salida produce y qué límites conviene tener presentes al aplicarlo.
La regresión lineal parte de una pregunta sencilla: si contamos con ejemplos previos y conocemos su resultado, ¿podemos encontrar una recta que los resuma razonablemente bien y usarla después para predecir nuevos casos? Este método no memoriza cada dato por separado, sino que aprende los parámetros que definen esa relación y los utiliza para generalizar.
Predecir un valor continuo a partir de datos variables de entrada.
Tiempo de llegada en Uber, vistas estimadas de un video, consumo eléctrico esperado.
Funciona mejor cuando el patrón observado se parece a una recta. Si el patrón de la relación entre los datos de entrada es curvo, la recta se queda corta.
¿Alguna vez jugaste a “Adivina el personaje”? Una persona piensa en alguien y tú intentas descubrir quién es haciendo preguntas que solo admiten respuesta de sí o no: “¿Es hombre?”, “¿Tiene más de 40 años?”, “¿Es famoso?”. Con preguntas bien elegidas, cada respuesta te acerca un poco más a la solución.
Un árbol de decisión funciona de manera parecida, pero con datos. A partir del conjunto de entrenamiento, el algoritmo busca cuál es la primera pregunta que más ayuda a separar los ejemplos en grupos distintos. Después elige otra pregunta para refinar aún más esa separación, y continúa así hasta llegar a una clasificación final.
Ejemplo: si quisiéramos construir un clasificador de spam, el árbol podría aprender reglas como estas:
Nadie programa esas reglas una por una. El árbol las aprende a partir de correos ya etiquetados, y usa esa experiencia para clasificar mensajes nuevos.
Clasificaciones con datos estructurados en forma de tabla: filas, columnas y variables claras.
Filtros de spam, decisiones de crédito, triage básico, detección de fraude simple.
Puede sobreajustarse y fallar cuando los datos nuevos son muy distintos a los del entrenamiento.
El clustering (agrupamiento) surge cuando tenemos muchos ejemplos, como canciones, compras o registros de pacientes, pero nadie los ha etiquetado. En ese escenario no buscamos una respuesta previa, sino descubrir si existen agrupaciones naturales a partir de las similitudes entre los elementos. K-Means aborda este problema colocando varios centros provisionales dentro del conjunto de datos, como si marcara puntos de referencia iniciales. A partir de ahí, calcula qué centro está más cerca de cada observación y le asigna esa observación a ese grupo. Después vuelve a calcular la posición de cada centro, esta vez usando el promedio de los puntos que quedaron asignados a él. Con los centros ya recalibrados, repite el mismo proceso: reasigna los puntos, recalcula los centros y vuelve a comparar. La idea es ir corrigiendo poco a poco la ubicación de esos centros hasta que los grupos apenas cambian y la partición final se vuelve estable.
Encontrar una estructura natural en datos sin respuestas predefinidas.
Segmentación de usuarios, agrupación de canciones, organización de noticias o clientes similares.
Tú decides cuántos grupos quieres (`k`). Si eliges mal ese número, los grupos dejan de tener sentido.
Aprendizaje no supervisado
Observa cómo el algoritmo toma una nube de canciones, propone centros iniciales y reorganiza grupos hasta encontrar una estructura estable.
Vista previa del clustering
Primero solo hay canciones como puntos en una nube. Después el algoritmo propone centros y reorganiza los grupos hasta estabilizarlos.
Al mirar una fotografía de un gato, normalmente no procesamos toda la imagen de golpe. Vamos reconociendo primero elementos sencillos, como bordes y contornos, y después otros más complejos, como texturas, formas y objetos completos. Las redes neuronales convolucionales siguen una lógica similar: sus capas aprenden a detectar rasgos visuales cada vez más complejos, desde detalles básicos hasta patrones que permiten identificar lo que aparece en la imagen.
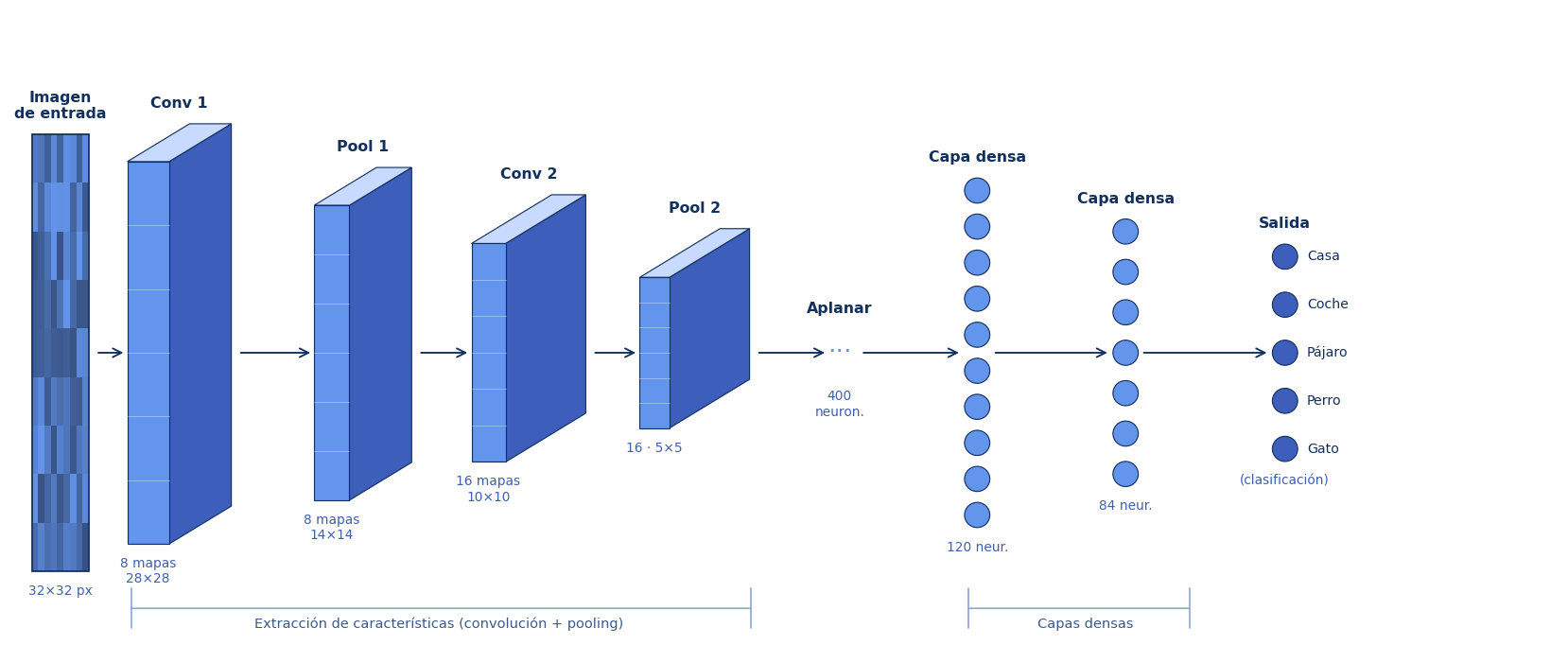
Clasificar o detectar patrones en imágenes y video.
Face ID, filtros de Instagram, moderación de contenido, asistentes de diagnóstico por imagen.
Necesita enormes cantidades de imágenes etiquetadas y mucho capacidad computacional. También puede fallar ante distorsiones inesperadas.
¿No habíamos dicho que ChatGPT usa redes neuronales? Sí. Los transformers son una arquitectura de red neuronal que mantiene las ideas de pesos, neuronas y entrenamiento por retropropagación (backpropagation) que viste en la sesión 2. La diferencia está en la forma en que organiza la información y en el mecanismo que usa para procesar secuencias completas.
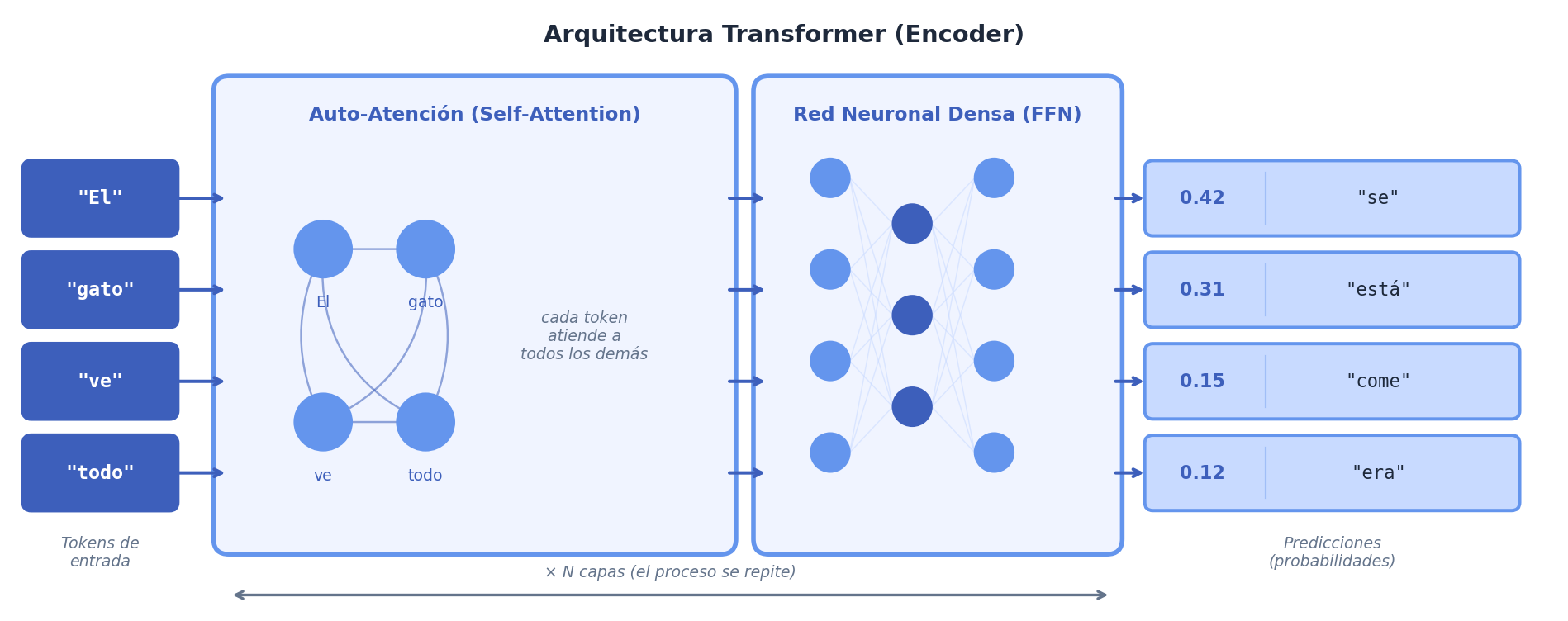
Cuando alguien te manda un mensaje como “¿ya llegaste?”, entiendes que esa frase depende de un contexto previo, de un destino implícito y de una intención concreta. Un transformer intenta hacer algo parecido con el texto: procesa la secuencia completa y estima qué palabras son más relevantes para interpretar cada una de ellas. Ese mecanismo se llama atención.
En lugar de leer una oración solo de izquierda a derecha, el modelo compara palabras entre sí y aprende relaciones que pueden estar muy separadas dentro del texto. Por eso puede traducir, resumir, completar frases o responder preguntas con más contexto que muchos modelos anteriores.
Traducción, generación de texto, resumen, chatbots, asistentes de código y otras tareas de lenguaje.
ChatGPT, Google Translate, Copilot, asistentes que completan frases o redactan respuestas.
Es costoso de entrenar, puede alucinar y hereda sesgos del texto con el que aprendió.
El aprendizaje por refuerzo aborda un tipo de problema diferente: ¿qué ocurre cuando no contamos con datos etiquetados, pero sí podemos dejar que un sistema actúe, observe el resultado de sus acciones y aprenda a corregirse? Aquí el objetivo no es predecir un valor ni asignar una categoría, sino aprender a tomar decisiones paso a paso. Un agente actúa sobre un entorno, recibe una recompensa o una penalización según lo que hizo, y poco a poco ajusta su forma de actuar para obtener mejores resultados.
Problemas donde no hay respuestas etiquetadas, pero sí un entorno para probar acciones y observar consecuencias.
Videojuegos, robótica, control industrial, optimización de rutas y simuladores complejos.
Necesita millones de intentos y, casi siempre, un simulador seguro. Pasar de una simulación al mundo real sigue siendo difícil.
Aprendizaje por refuerzo
Un agente aprende a jugar Mario repitiendo acciones y observando cuáles le resultan y cuáles no.
Vista previa del ciclo de refuerzo
Verás tres intentos. Lo importante no es solo si cruza o no, sino cómo la recompensa modifica la política del agente.
A continuación encontrarás seis problemas cotidianos. Para cada uno, selecciona el método o arquitectura que mejor encaja según el mapa de la sesión. Cuando hayas asignado todos, verifica tus respuestas.
Actividad — mapa de métodos
Asigna un algoritmo a cada escenario. Recuerda las dos preguntas del mapa: ¿tienes respuestas etiquetadas? ¿qué tipo de salida necesitas?
Vista previa de la actividad
Seis problemas esperan tu clasificación. Abre la actividad para empezar.
Seis problemas cotidianos. Tu tarea es asignar el algoritmo de IA más apropiado a cada uno.
El objetivo es aprender a identificar qué tipo de problema se resuelve mejor con qué tipo de método.
Antes de ver la tabla comparativa: ¿cuál sería la primera pregunta que harías antes de elegir un modelo de IA para un problema que encuentres en tu día a día?
Aquí tienes un resumen de la sesión.
| Método | Tipo de problema | Analogía | App que la usa | Limitación |
|---|---|---|---|---|
| Regresión lineal | Predecir un número continuo | Estimar algo con una recta | Uber, Google Maps | Solo captura relaciones lineales simples |
| Árbol de decisión | Clasificar con datos estructurados | Juego de preguntas de sí o no | Spam, riesgo, triage | Puede sobreajustarse y fallar fuera de distribución |
| K-Means | Agrupar sin etiquetas | Buscar zonas parecidas en una nube de puntos | Spotify, Netflix, segmentación de mercado | Tú eliges cuántos grupos quieres |
| CNN | Clasificar imágenes o video | Capas que ven bordes → formas → objetos | Face ID, filtros, moderación | Necesita muchos datos visuales etiquetados |
| Transformer | Entender o generar secuencias | Autocompletado que sí usa contexto | ChatGPT, Google Translate, Copilot | Es costoso y puede alucinar |
| Refuerzo | Aprender a actuar por ensayo y error | Practicar hasta que la recompensa mejore | Videojuegos, robótica, control y optimización | Necesita simulación y muchísimos intentos |
Elige una app que usas todos los días. ¿Qué tipo de problema resuelve su IA? Usa el mapa de las dos preguntas para ubicarla.
Piensa en un problema que quisieras resolver con IA. Puede ser algo de tu escuela, tu hobby o tu comunidad. ¿Qué método usarías? ¿Qué datos necesitarías?
Las limitaciones importan. Si tuvieras que explicarle a alguien por qué un transformer no es la solución a todo, ¿qué le dirías?
Condénsalo en una regla. Si tuvieras que resumir esta sesión en una frase práctica, ¿cuál sería?
No hay respuestas correctas o incorrectas. Lo importante es que el mapa empiece a formar parte de tu manera de pensar sobre la IA.
El algoritmo correcto no es el más complejo ni el más famoso. Es el que mejor encaja con el tipo de problema, la forma de la salida y los datos disponibles. La clave está en aprender a formular la pregunta adecuada para elegir la mejor herramienta.
Scrollytelling visual para entender cómo un árbol de decisión construye sus preguntas paso a paso.
Colección de ensayos visuales sobre algoritmos clave de machine learning.
GPT-2 en vivo en tu navegador para observar atención, contexto y predicción de tokens.
Demo interactiva para ver cómo el clustering mueve centros y reagrupa puntos paso a paso.
Experimenta con redes neuronales y observa cómo cambian sus fronteras de decisión.
Curso introductorio gratuito en español con contexto amplio sobre varios de los métodos que viste aquí.